

记一次gelu算子优化的学习过程,gelu可以代表一类element-wise算子。由于我读文档获取的信息非常琐碎,打算用Analysis-Driven Optimization(分析驱动优化 ADO)的方式写篇博客梳理一下思路,作为学习笔记。
1.baseline
首先gelu的公式为
gelu公式:x / 2 * (1 + tan(0.7978845608028654 * (x + 0.044714998453855515 * x^3)))
根据公式我们用最朴素的实现element-wise的思路,即每个线程负责一个子元素的处理
in out
+---+ +---------+
| 0 | ---thread1--> | gelu(0) |
+---+ +---------+
| 1 | ---thread2--> | gelu(1) |
+---+ +---------+
|...| ... | ... |
+---+ +---------+
| 8 | ---threadn--> | gelu(8) |
+---+ +---------+不难写出下面的第一版
__global__ void gelu_base_kernel(float* out, float *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
#pragma unroll
for(int i = tid; i < n; i += blockDim.x * gridDim.x) {
out[i] = gelu<float>(in[i]);
}
}这里用到了两个技巧
- 网格跨步循环(Grid-Stride loops)(如果你不知道这个技巧可以参考这里👈),即第4行代码处
i += blockDim.x * gridDim.x我们重复利用一个小的grid中的线程对数据多次循环操作,效果类似于一次性申请了一个覆盖全数据范围的grid,这样的好处是可以兼容任意形状和数量的block和grid,方便后续对block和grid尺寸的调整。 - 循环展开(loop unrolling),这是一种常见的优化手段,只是C++中编译器会自动做到这点,这个操作带来的提速是相当可观的,我们使用#pragma unroll就能实现。
其中gelu函数的代码为:
template<typename T>
__device__ __host__ __forceinline__ T gelu(T x) {
T alpha = static_cast<T>(0.7978845608028654);
T beta = static_cast<T>(0.044714998453855515);
const T half = static_cast<T>(0.5);
const T one = static_cast<T>(1);
const T tanh_in = alpha * (x + beta * x * x * x);
const T tanh_out = tanh(tanh_in);
return half * x * (one + tanh_out);
}在64MB的数据量上测得运行时间为257.70us(cpu版本执行时间为461.139ms)
使用Nsight Compute的Roofline分析可以看到此时处于Memory Bound,这意味着此时需要考虑的优化方向是访存而不是计算。
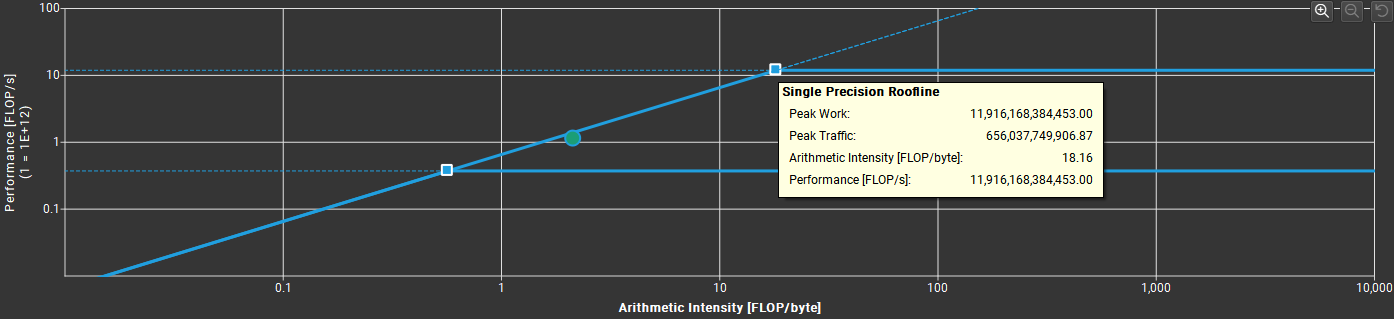
2.合并访存
我们可以考虑合并访存。
关于全局内存的访问模式,有合并(coalesced)与非合并(uncoalesced)之分。合并访问指的是一个线程束对全局内存的一次访问请求(读或写)导致最少数量的数据传输;否则称访问是非合并的。定量地,可以定义合并度,它等于线程束请求的字节数除以 由该次请求导致的所有数据传输的字节数。合并度可以理解为资源利用率。如果数据传输中处理的数据都是线程束所需要的,那么合并度就是100%,访存的资源利用率也就是100%,对应的访问模式为合并访存。利用率越高,核函数的访存性能就更好;反之,显存带宽利用率较低。

这里需要理解request和sector这两个指标,从warp中发出的全局内存访存指令会被发送到L1中,如果L1未命中会被转发到L2,所以我们可以在L1的metrics中获取到访问全局内存的request和sector指标,关于request和sector的含义由于没有找到官方的说明,我的理解是一个LDG.E.SYS (SASS)指令就对应一个request,表示一次性从global memory中取32bit的数据,由于cuda的SIMT架构,一个warp中的每个线程都需要取32bit,那么总共需要取4Byte*32 = 128Byte的数据,一个sector大概表示一个32Byte的硬件存储单元,因此需要4个sector。由于线程中的register的大小都是32bit,一个指令LDG指令取32bit也是非常合理的。
我们在nvcc编译时加上-lineinfo参数可以在Nsight Compute中看到源码和SASS,PTX之间逐行的对应关系。
nvcc -arch=sm_75 -lineinfo -o ./dist/gelu ./gelu.cu #编译
ncu --section MemoryWorkloadAnalysis_Tables --open-in-ui ./dist/gelu.exe #生成nsight compute报告并自动在gui中打开有关Nsight Compute和nvcc的使用技巧,有时间会写篇博客专门讨论
在source页面中我们可以看到当前的访存指令确实是LDG.E.SYS
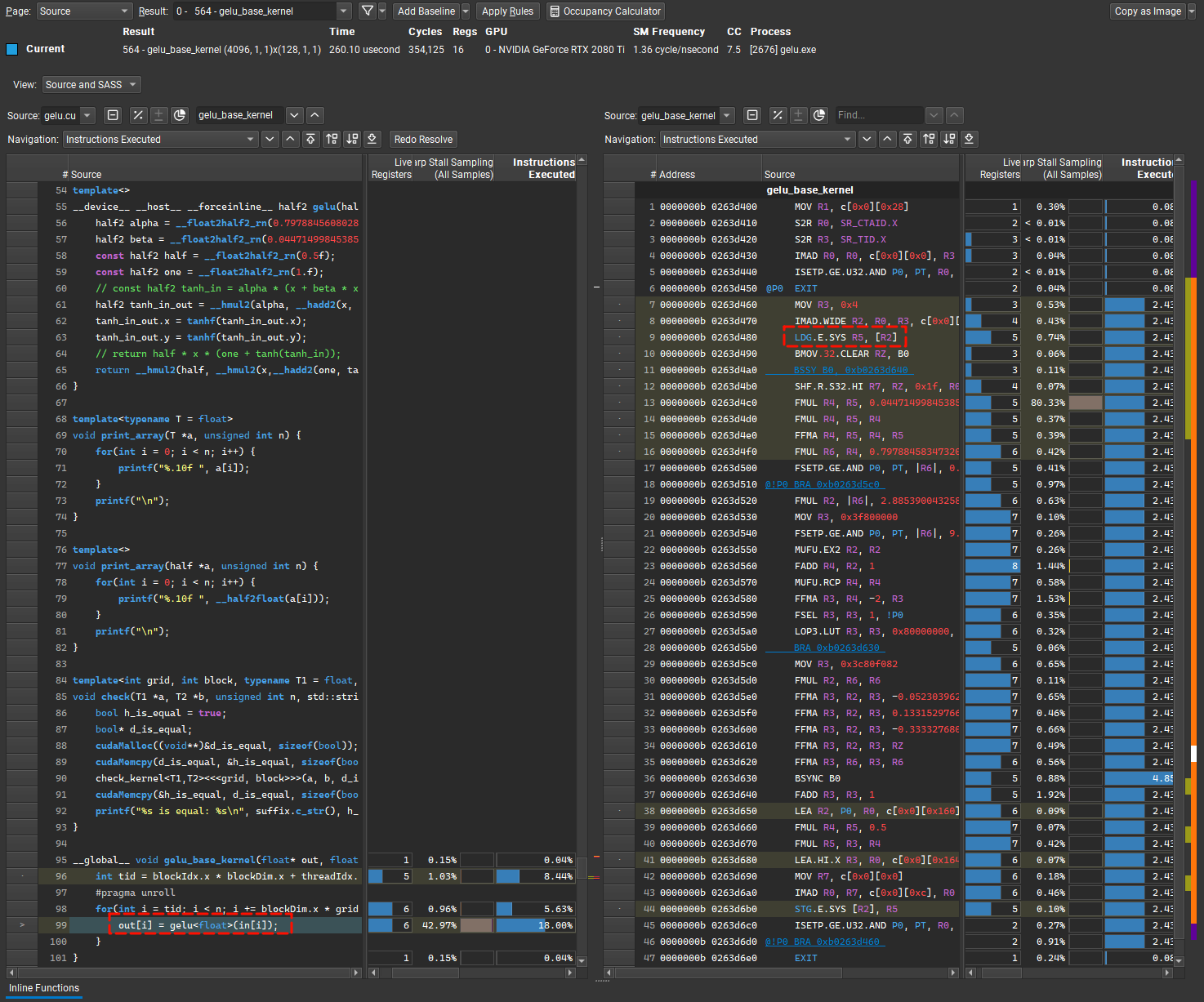
page: 切换到details可以看到Sectors/Req的值为4,符合我们之前的猜测。
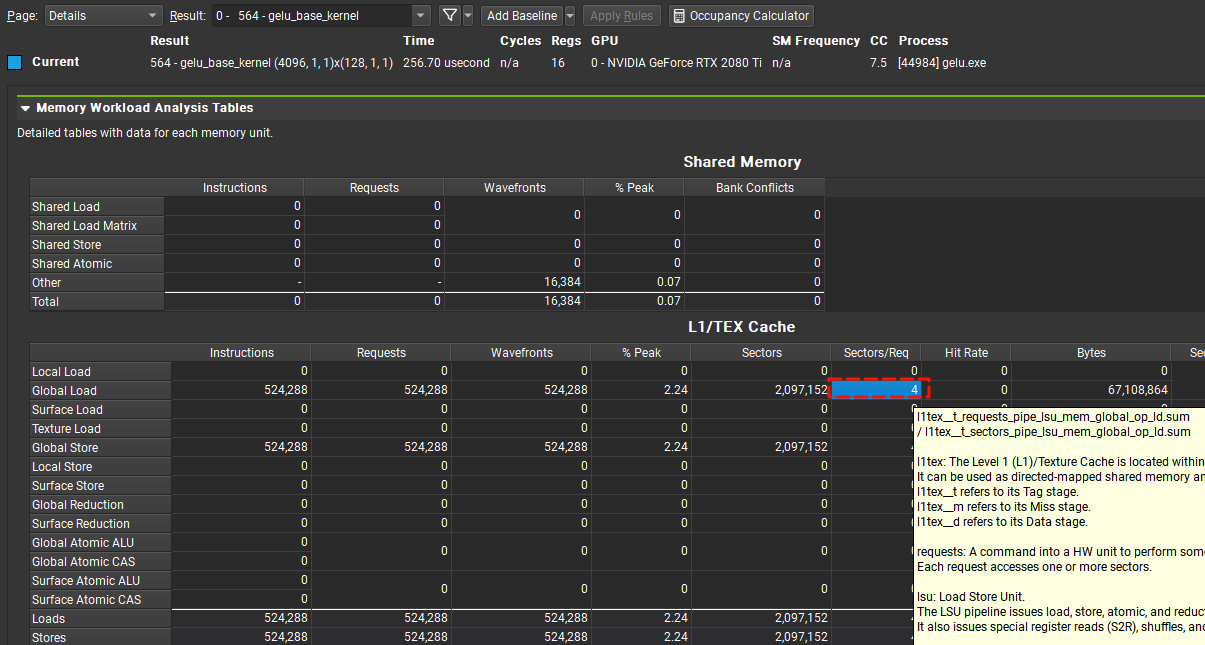
实际上除了一次读取32bit的LDG.E.SYS指令还有一次读取64bit的LDG.E.64.SYS和一次读取128bit的LDG.E.128.SYS
⚠Note :
存储也有镜像的指令分别为
STG.E.SYS,STG.E.64.SYS,STG.E.128.SYS
cuda提供了float2、float4类型,即2、4个float的合并,但是没有提供这种类型的运算操作,所以只能用来提高访存效率,这种也叫做向量化访存。
代码也非常简单,只需要让baseline中的每个线程额外多处理一个float,因此总共需要参与的线程数量也需要除以2(对应n/2)
__global__ void gelu_vector2_kernel(float* out, float *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int remain = n % 2;
#pragma unroll
for(int i = tid; i < n/2; i += blockDim.x * gridDim.x) {
float2 tmp = reinterpret_cast<float2*>(in)[i];
tmp.x = gelu<float>(tmp.x);
tmp.y = gelu<float>(tmp.y);
reinterpret_cast<float2*>(out)[i] = tmp;
}
if ( tid < remain) {
out[n-1-tid] = gelu<float>(in[n-1-tid]);
}
}需要注意的是,这里有个remain的逻辑用来处理剩余可能存在的不能被打包成float2类型的末尾几个数据。
float4同理
__global__ void gelu_vector4_kernel(float* out, float *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int remain = n % 4;
#pragma unroll
for(int i = tid; i < n/4; i += blockDim.x * gridDim.x) {
float4 tmp = reinterpret_cast<float4*>(in)[i];
tmp.x = gelu<float>(tmp.x);
tmp.y = gelu<float>(tmp.y);
tmp.z = gelu<float>(tmp.z);
tmp.w = gelu<float>(tmp.w);
reinterpret_cast<float4*>(out)[i] = tmp;
}
if ( tid < remain) {
out[n-1-tid] = gelu<float>(in[n-1-tid]);
}
}float2和float4分别对应了LDG.E.64.SYS和STG.E.64.SYS,LDG.E.128.SYS和STG.E.128.SYS
ⓘ Info:
n % 4和n & (4-1)的SASS代码相同,即求余运算已经被编译器优化过了(在cuda版本12.3中)。
在RoofLine model中可以看到,合并访存使得坐标点右移,说明访存的障碍在降低,算力逐渐被用起来了。
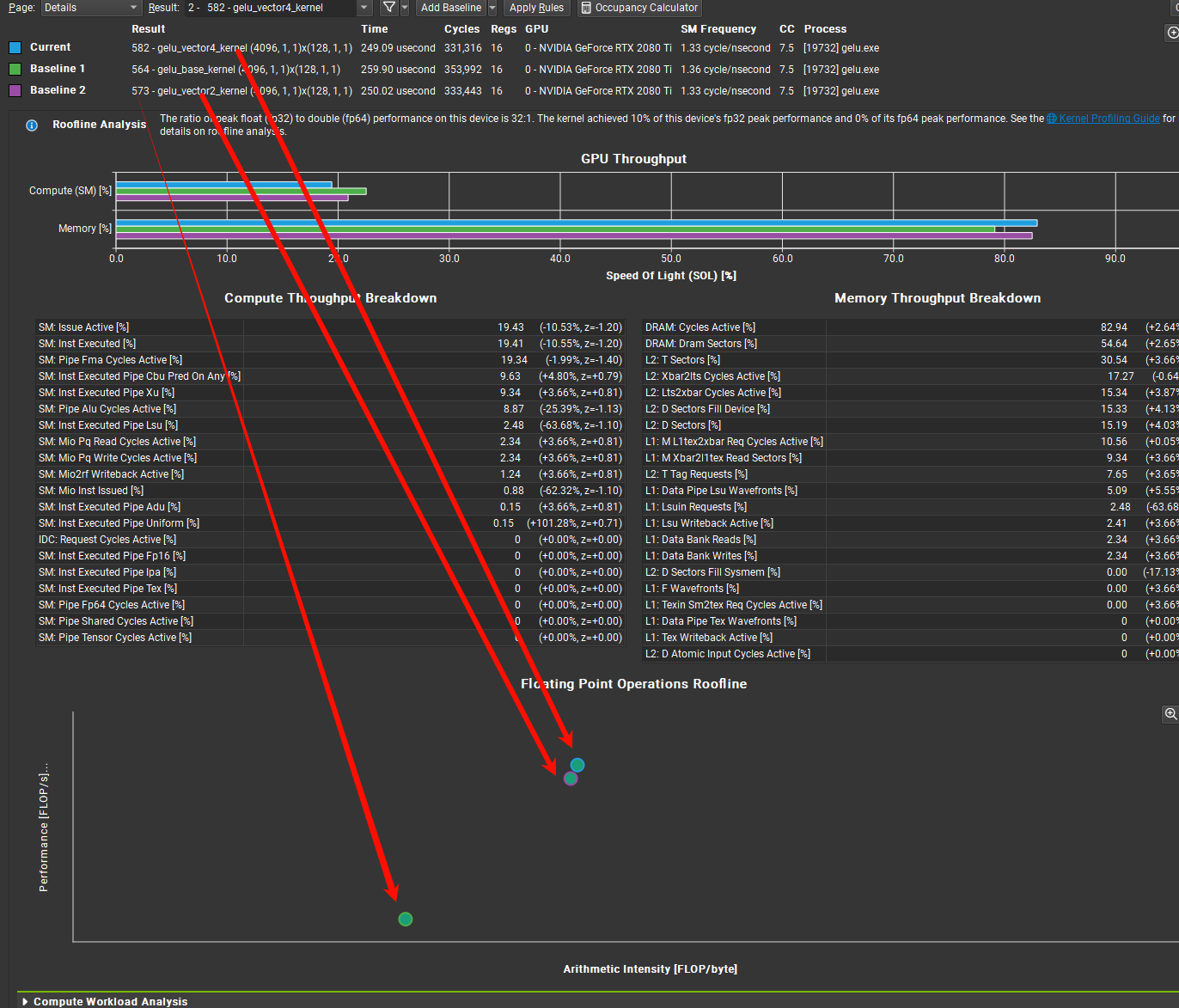
P.S. :在右移但是不多,这里已经放大了很多倍
此时request和sector值为
gelu_base_kernel(float *, float *, unsigned int) (4096, 1, 1)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 7.5
Section: Command line profiler metrics
----------------------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
----------------------------------------------- ----------- ------------
l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum request 524,288
l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum sector 2,097,152
----------------------------------------------- ----------- ------------
gelu_vector2_kernel(float *, float *, unsigned int) (4096, 1, 1)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 7.5
Section: Command line profiler metrics
----------------------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
----------------------------------------------- ----------- ------------
l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum request 262,144
l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum sector 2,097,152
----------------------------------------------- ----------- ------------
gelu_vector4_kernel(float *, float *, unsigned int) (4096, 1, 1)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 7.5
Section: Command line profiler metrics
----------------------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
----------------------------------------------- ----------- ------------
l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum request 131,072
l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum sector 2,097,152
----------------------------------------------- ----------- ------------ⓘ Info:
上面的查询使用的指令为
ncu --metrics l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum,l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum ./dist/gelu.exe
可以看到访存次数(request)每次减少一半,每次访存带回的数据量sector/request值在升高。
执行时间也在缩短

3.半精度
半精度好像是在cuda7.5版本开始使用,对应的具体从什么算力和架构开始可以参考这里👈,可以确定的是CC 7.5即以上,也就是turning架构(GeForce 2080Ti == 俺的)和后面的都支持了。
半精度是half,16bit划分为 0|00000|0000000000 分别为 符号位|指数|小数 ,其中指数范围为5位,远小于fp32的8位,强转会有上下溢问题,而bf16则不会有这种问题。
在cuda中,可以使用half2类型,他可以把两个half塞进一个float里,这样访存密度又能提升一倍,并且,还有half2专用的指令,可以使用SIMD的方式一条指令同时算两个half也就是直接处理一个half2类型而不用像float2那样拆开来分别算,Ampere架构开始支持把Bfloat16这样搞,孩子都快馋哭了。
ⓘ Info:
fp16在推理和训练方面都有很多应用,一般来说fp16的运算效率是float的两倍,如2080ti在使用fp16的情况下可以到23TFLOPS是fp32时的两倍(3090的fp16也才29TFLOPS,性价比可以想象),数值范围小也有补救措施在混合精度训练中会有一系列方法如 Loss Scaling。
为了实现上面提到的SIMD的效果,需要模板特化一下gelu函数,使得对于half2类型使用完全定制的逻辑,关于half2能用什么SIMD的函数,可以参考这里👈,下面代码中tanh没有对应的SIMD指令所以拆开来算了。
template<>
__device__ __host__ __forceinline__ half2 gelu(half2 x) {
half2 alpha = __float2half2_rn(0.7978845608028654);
half2 beta = __float2half2_rn(0.044714998453855515);
const half2 half = __float2half2_rn(0.5f);
const half2 one = __float2half2_rn(1.f);
half2 tanh_in_out = __hmul2(alpha, __hadd2(x, __hmul2(beta,__hmul2(x, __hmul2(x, x)))));
tanh_in_out.x = tanhf(tanh_in_out.x);
tanh_in_out.y = tanhf(tanh_in_out.y);
return __hmul2(half, __hmul2(x,__hadd2(one, tanh_in_out)));
}我们先在baseline的基础上改一个half2类型看看能提多少速度。
__global__ void gelu_half2_kernel(half* out, half *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int remain = n % 2;
#pragma unroll
for(int i = tid; i < n/2; i += blockDim.x * gridDim.x) {
reinterpret_cast<half2*>(out)[i] = gelu<half2>(reinterpret_cast<half2*>(in)[i]);
}
if ( tid < remain) {
out[n-1-tid] = gelu<half>(in[n-1-tid]);
}
}| function name | Duration(us) |
|---|---|
| gelu_base_kernel | 257.82 |
| gelu_vector2_kernel | 249.70 |
| gelu_vector4_kernel | 249.15 |
| gelu_half2_kernel | 136.83 |
时间大约缩短了一半。但是实际上我发现精度也下降到了0.001,低于0.001的位数会有差异。
按照上面的合并访存思路,我也分别使用float2,float4来分别完成64位和128位的合并,当然也有其他方法,但是需要建struct手动做内存对齐。
__global__ void gelu_vector2_half2_kernel(half* out, half *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int remain = n % 4;
// using ArrT = AlignedVector<half2, 2>;
using ArrT = float2;
#pragma unroll
for(int i = tid; i < n/4; i += blockDim.x * gridDim.x) {
ArrT p = reinterpret_cast<ArrT*>(in)[i];
#pragma unroll
for(int j = 0; j < 2; j++) {
reinterpret_cast<half2*>(&p)[j] = gelu<half2>(reinterpret_cast<half2*>(&p)[j]);
}
reinterpret_cast<ArrT*>(out)[i] = p;
}
if ( tid < remain) {
out[n-1-tid] = gelu<half>(in[n-1-tid]);
}
}__global__ void gelu_vector4_half2_kernel(half* out, half *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int remain = n % 8;
// using ArrT = AlignedVector<half2, 4>;
using ArrT = float4;
#pragma unroll
for(int i = tid; i < n/8; i += blockDim.x * gridDim.x) {
ArrT p = reinterpret_cast<ArrT*>(in)[i];
#pragma unroll
for(int j = 0; j < 4; j++) {
reinterpret_cast<half2*>(&p)[j] = gelu<half2>(reinterpret_cast<half2*>(&p)[j]);
}
reinterpret_cast<ArrT*>(out)[i] = p;
}
if ( tid < remain) {
out[n-1-tid] = gelu<half>(in[n-1-tid]);
}
}| function name | Duration(us) |
|---|---|
| gelu_base_kernel | 259.36 |
| gelu_vector2_kernel | 249.79 |
| gelu_vector4_kernel | 249.15 |
| gelu_half2_kernel | 136.83 |
| gelu_vector2_half2_kernel | 127.23 |
| gelu_vector4_half2_kernel | 125.82 |
补充使用cutlass/cute实现的版本
引用自cutlass/cute项目文档|GPT4o翻译:
CuTe 是一组用于定义和操作分层多维线程和数据布局的 C++ CUDA 模板抽象。CuTe 提供了 Layout 和 Tensor 对象,这些对象紧凑地封装了数据的类型、形状、内存空间和布局,同时为用户执行复杂的索引操作。这使得程序员可以专注于算法的逻辑描述,而 CuTe 负责机械式的记账工作。借助这些工具,我们可以快速设计、实现和修改所有密集线性代数操作。
关于cute的使用可以参考
cutlass/media/docs/cute/00_quickstart.md at v3.2.0 · NVIDIA/cutlass (github.com)
cute 之 Tensor - 知乎 (zhihu.com)
使用cute中的tensor对象可以轻松实现逻辑地址和物理地址的映射,下面代码中我们使用tensor表示global memory中的in和out,并将他们分块后拷贝到线程中的寄存器上,我们使用8个half的分块来访存,编译器会自动优化为LDG.E.128.SYS和STG.E.128.SYS。速度和gelu_vector4_half2_kernel非常接近。
__global__ void gelu_tensor_half2_kernel(half* out, half *in , unsigned int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = tid; i < (n+7)/8; i += blockDim.x * gridDim.x) {
Tensor tin = make_tensor(make_gmem_ptr(in), make_shape(n));
Tensor tout = make_tensor(make_gmem_ptr(out), make_shape(n));
Tensor tinr = local_tile(tin, make_shape(Int<8>{}), make_coord(i));
Tensor toutr = local_tile(tout, make_shape(Int<8>{}), make_coord(i));
Tensor tinR = make_tensor_like(tinr);
copy(tinr, tinR);
auto tinR2 = recast<half2>(tinR);
#pragma unroll
for(int x = 0; x < size(tinR2); x++) {
tinR2(x) = gelu<half2>(tinR2(x));
}
auto tinRx = recast<half>(tinR2);
copy(tinRx, toutr);
}
}| function name | Duration(us) |
|---|---|
| gelu_base_kernel | 259.36 |
| gelu_vector2_kernel | 249.79 |
| gelu_vector4_kernel | 249.15 |
| gelu_half2_kernel | 136.83 |
| gelu_vector2_half2_kernel | 127.23 |
| gelu_vector4_half2_kernel | 125.82 |
| gelu_tensor_half2_kernel | 125.75 |
代码地址:cudaLearn/gelu.cu at main · HeduAiDev/cudaLearn (github.com)


Comments | NOTHING